Infrastructure Excellence
Sovereign AI Infrastructure Fabric
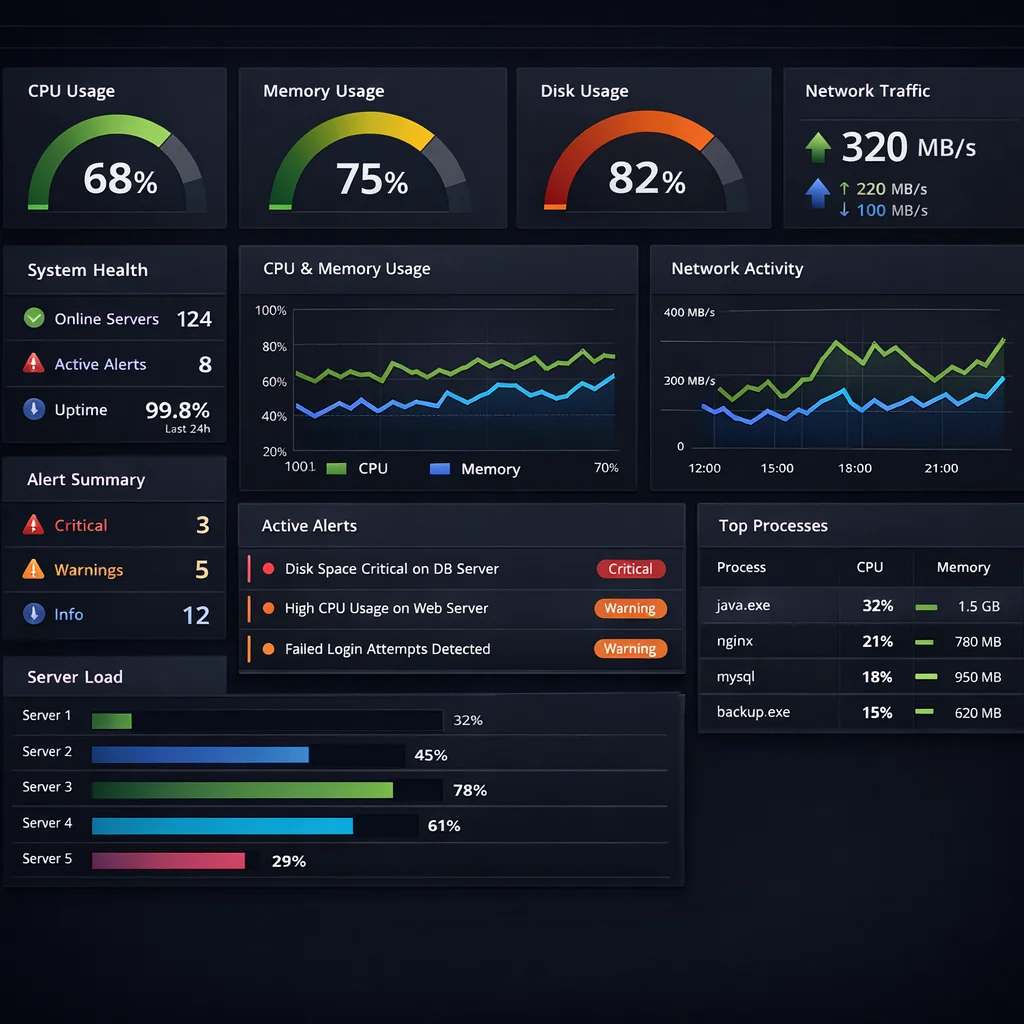
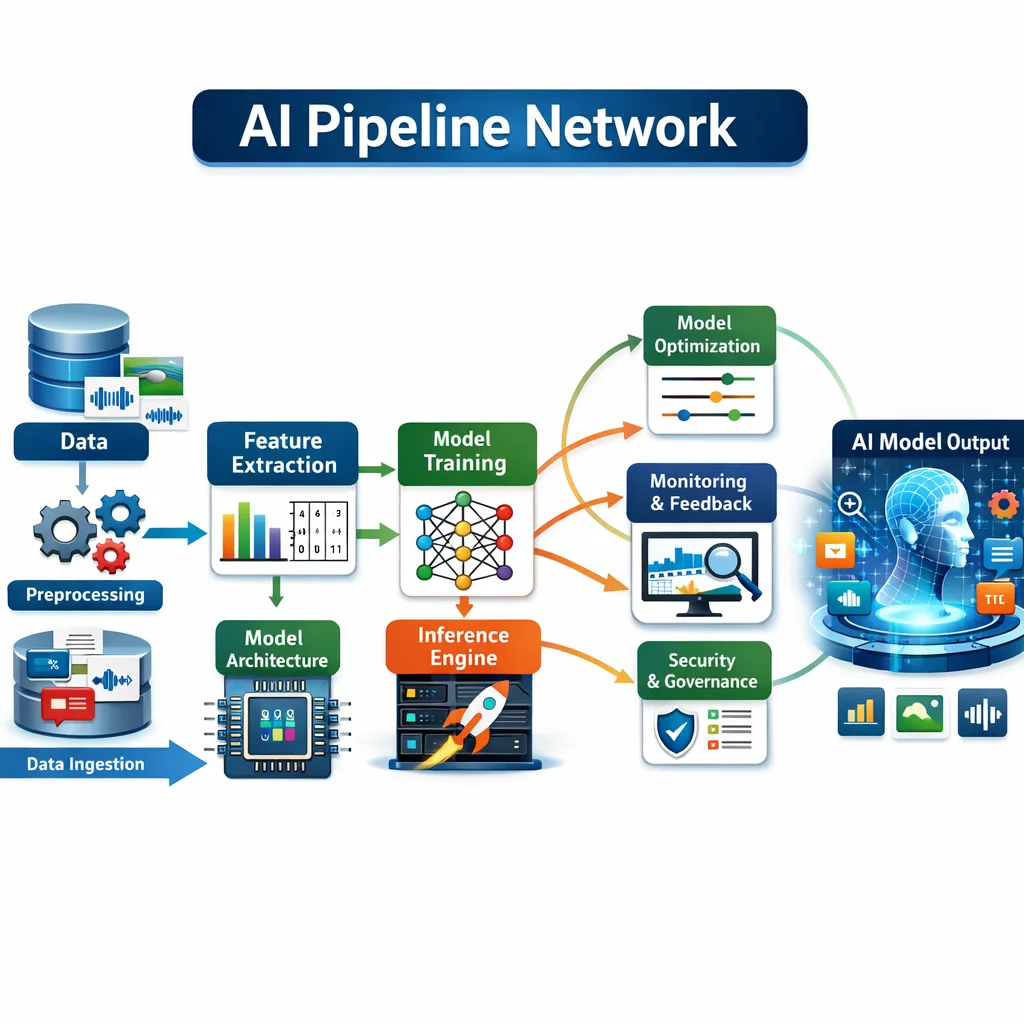
Production-grade on-premise infrastructure powering AI/ML workloads, data services, and observability using a containerized stack on TrueNAS Scale — eliminating six-figure annual cloud dependency while maintaining enterprise SLA standards.
50+
AI/ML Services
$0
Cloud API Costs
99.9%
Uptime SLA
247GB
RAM Capacity