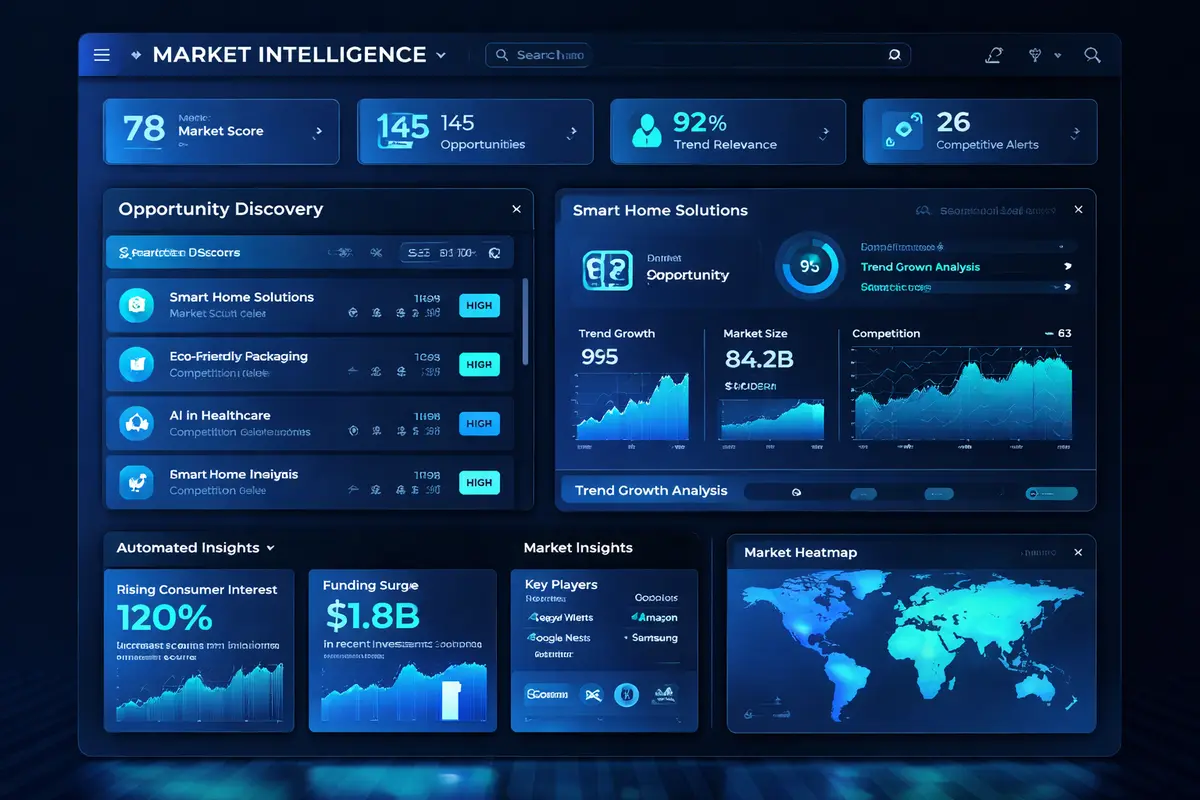
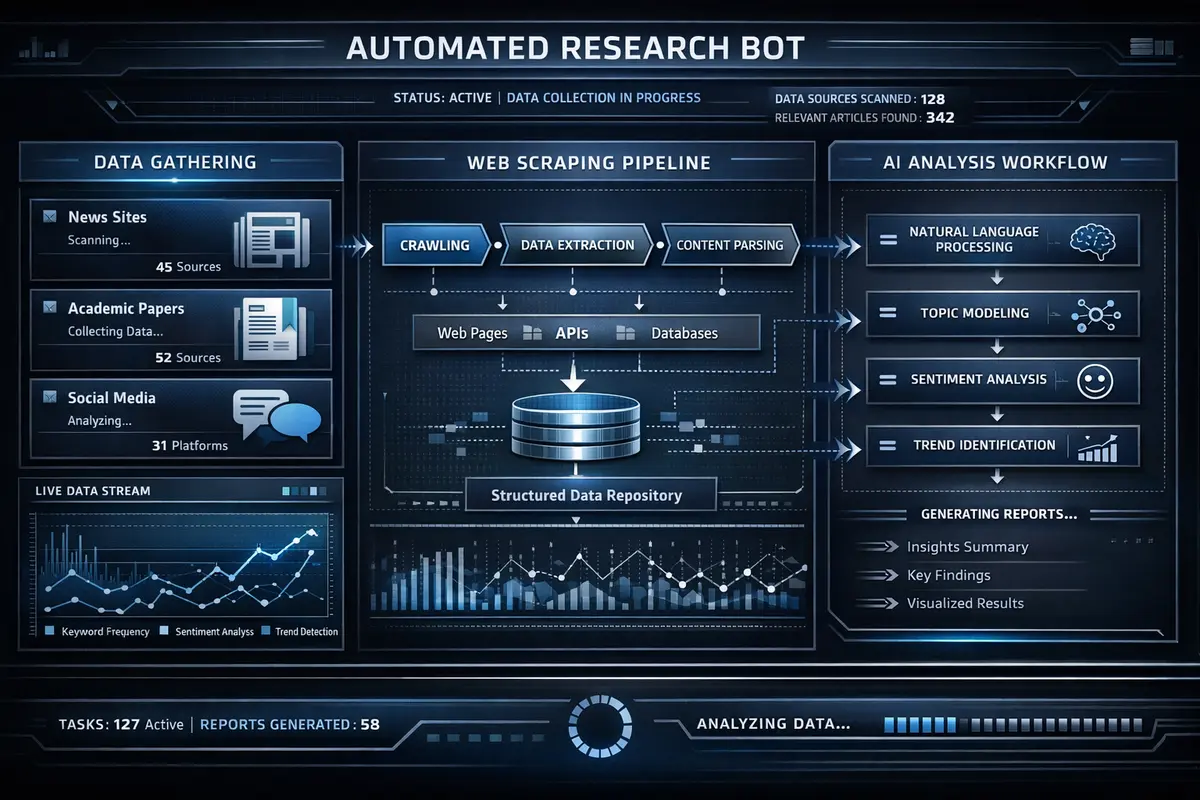
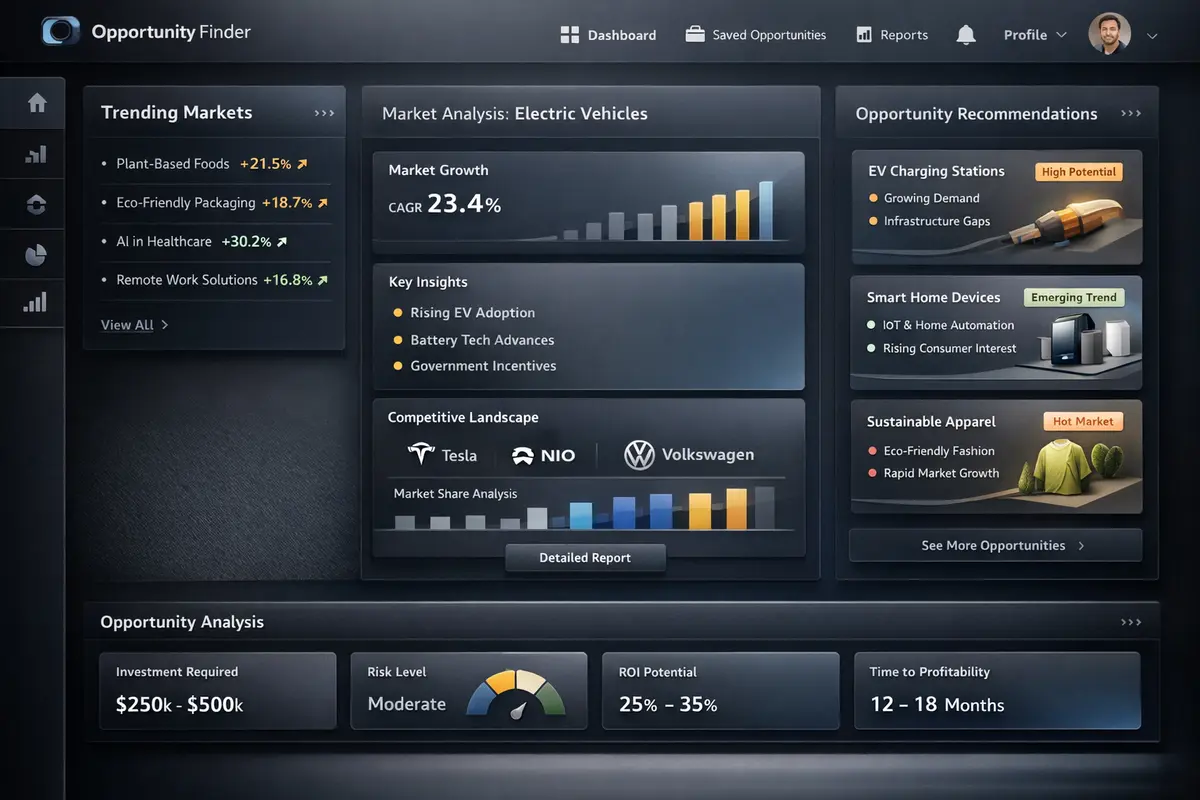
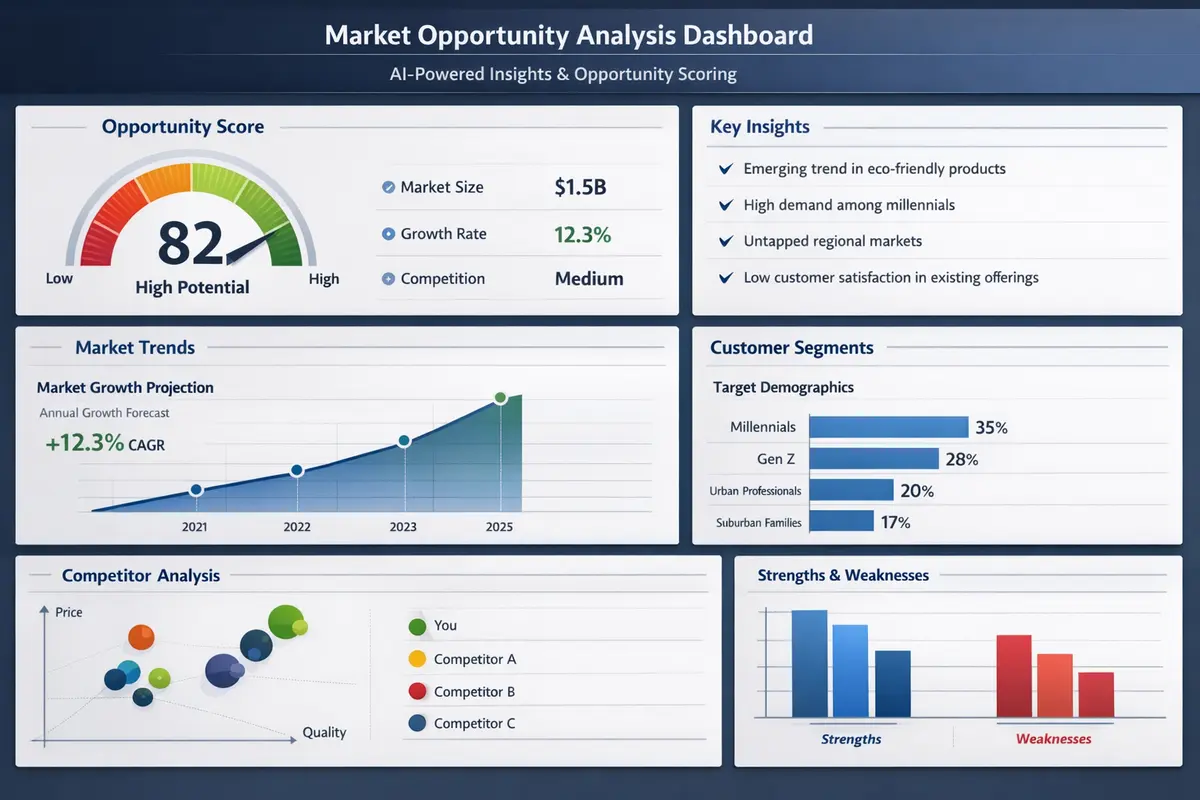
Multi-Source Ingestion Layer
The pipeline begins with parallel multi-source ingestion. A custom Reddit scraper built on the PRAW (Python Reddit API Wrapper) library monitors configurable subreddits including r/SideProject, r/Entrepreneur, r/SaaS, r/microsaas, and r/startups. The scraper respects Reddit's rate limits through exponential backoff and maintains a persistent seen-post cache to avoid re-processing content across ingestion cycles. For each post, the scraper captures the title, body text, comment threads above a configurable karma threshold, author metadata, and engagement metrics including upvote ratio and comment velocity.
The Indie Hackers scraper uses BeautifulSoup to parse discussion threads, milestone posts, and product launch announcements. Because Indie Hackers does not provide a public API, the scraper implements session management with rotating user agents and request throttling to maintain reliable access. Google dorking queries are constructed from templates that combine industry-specific keywords with site operators, date ranges, and content type filters to surface early-stage signals that traditional market research tools miss entirely.
Raw text from each source passes through a preprocessing stage that normalizes formatting, strips HTML entities, extracts named entities (company names, product names, revenue figures, user counts), and removes noise including boilerplate footer text, moderator notices, and duplicate content fragments. The deduplication engine computes locality-sensitive hashes of each opportunity to prevent redundant analysis when the same opportunity surfaces across multiple channels or in subsequent scrape cycles.