AI Market Intelligence
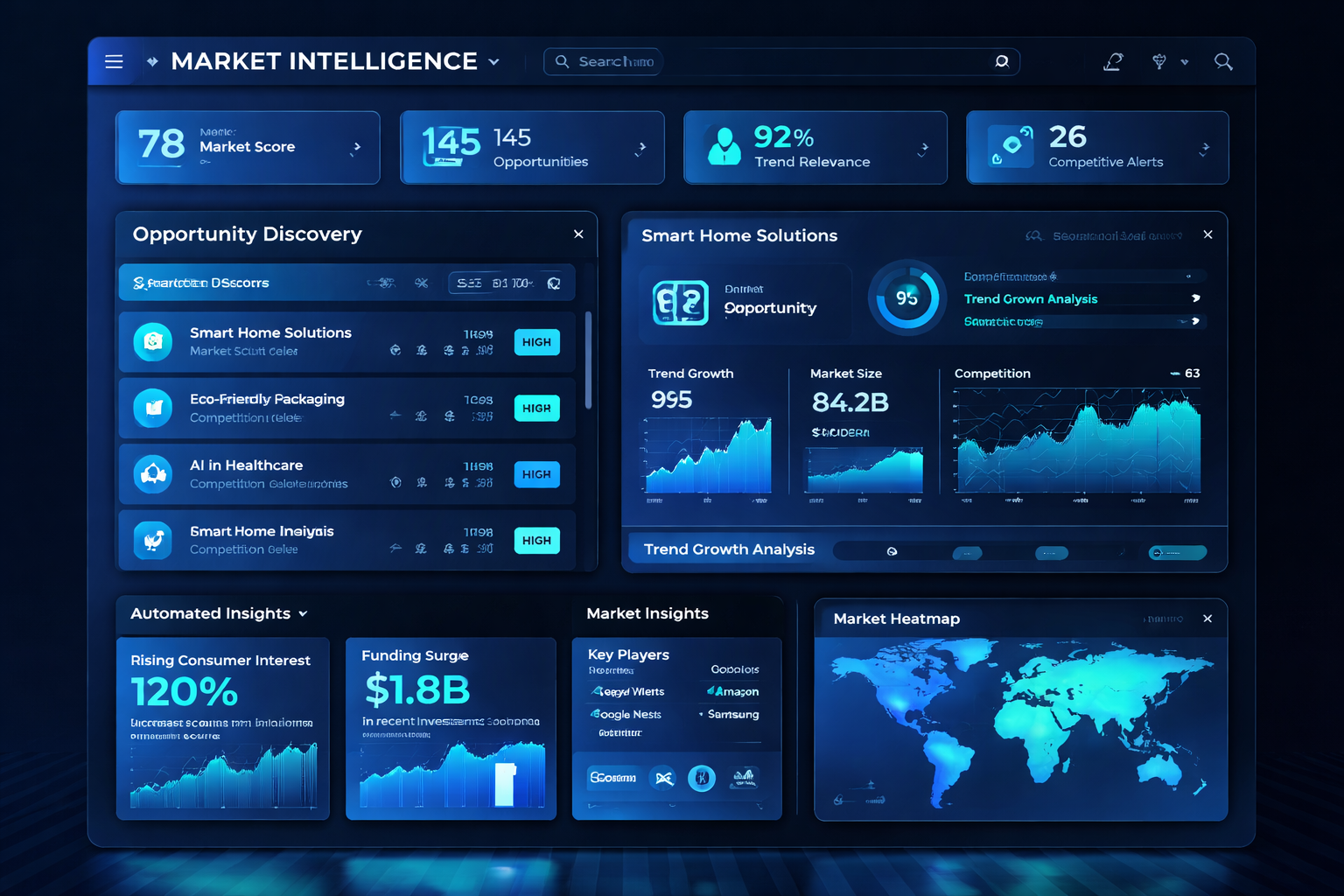
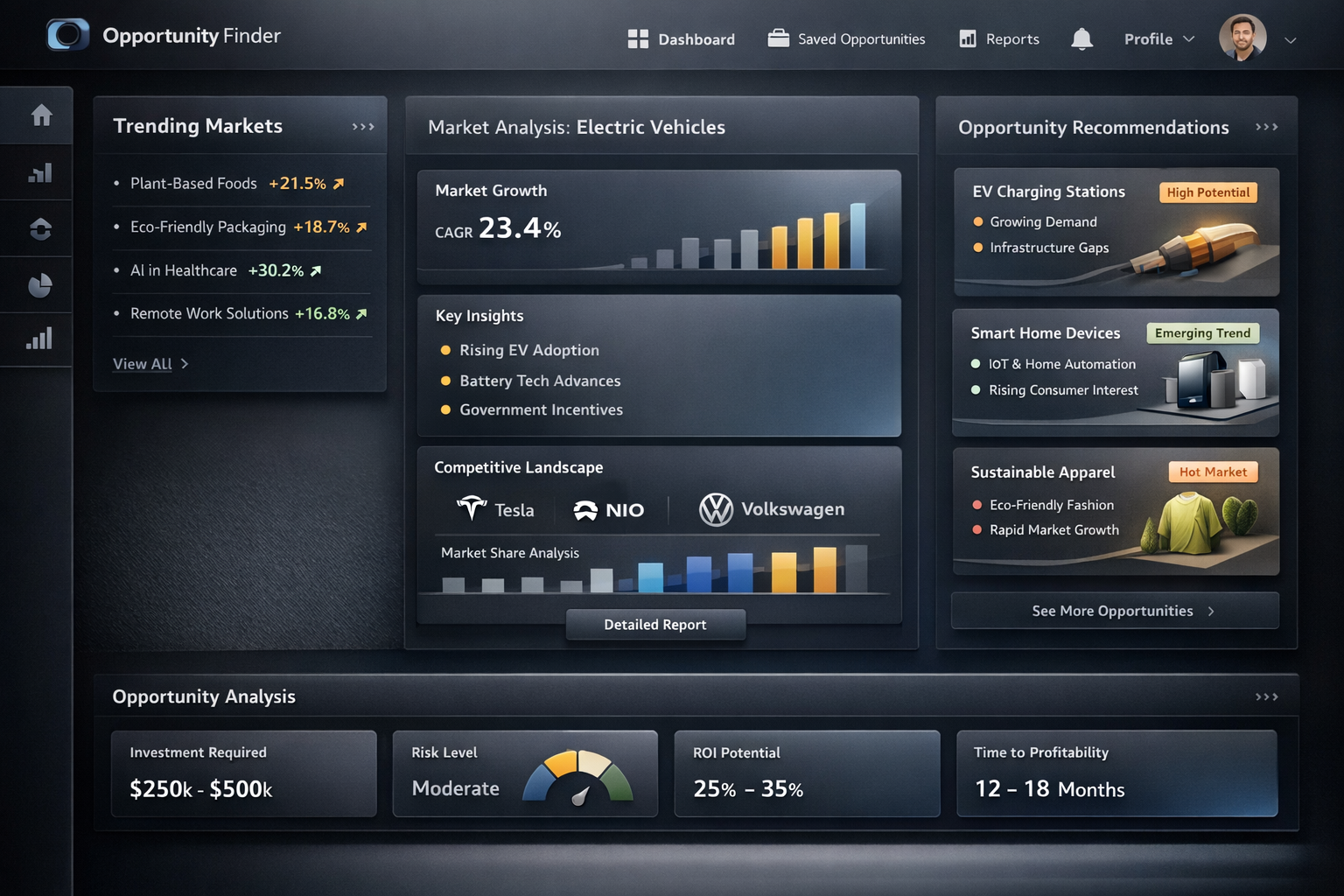
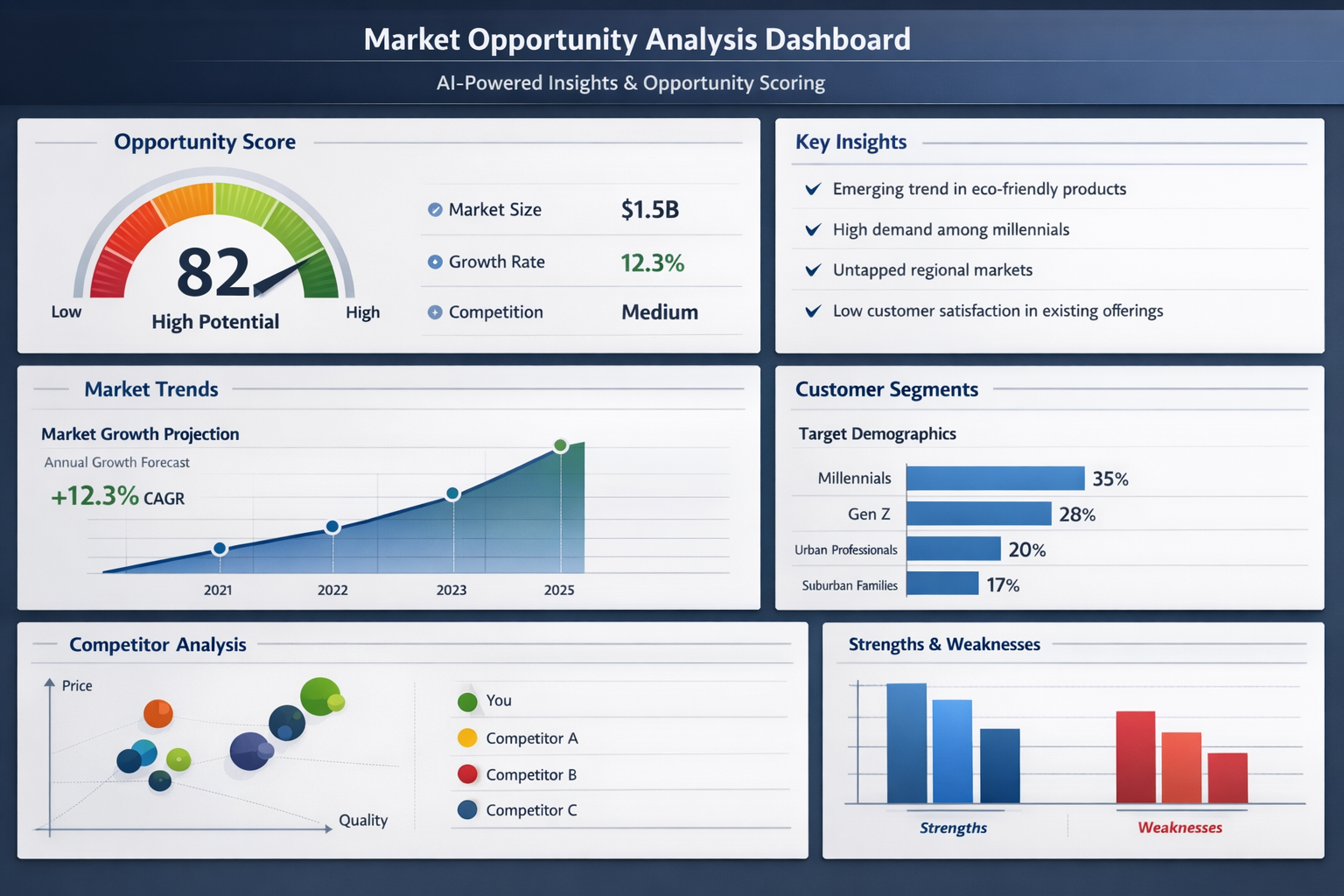
AI Market Intelligence Engine
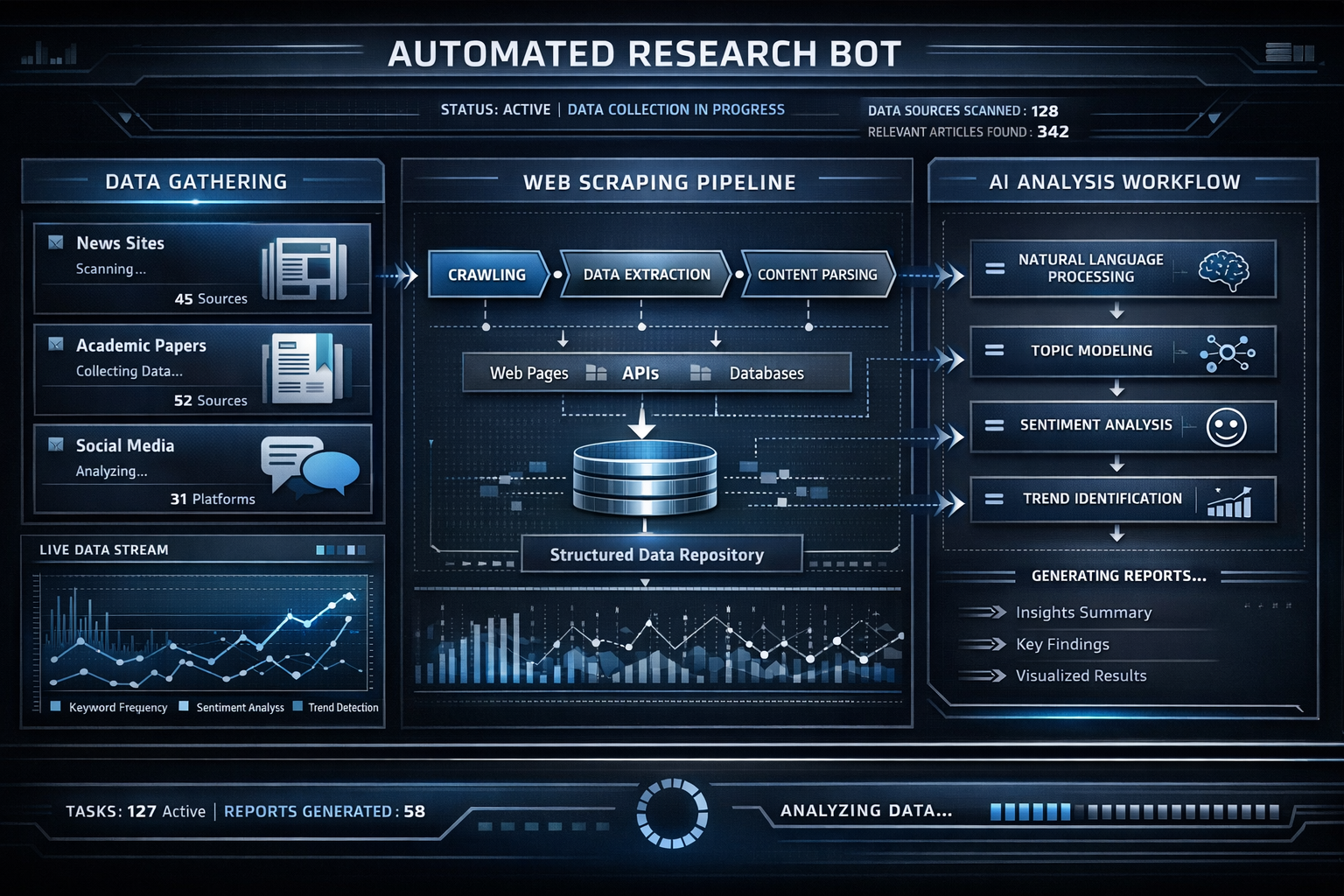
Proprietary AI pipeline that autonomously discovers and scores revenue opportunities across multiple data sources using local LLM inference and RAG-based semantic search - delivering institutional-grade market intelligence at zero marginal cost per query.
$0
Per Query Cost
Multi
Source Ingestion
RAG
Semantic Search
Local
LLM Inference