Reproducible Evaluation Protocols
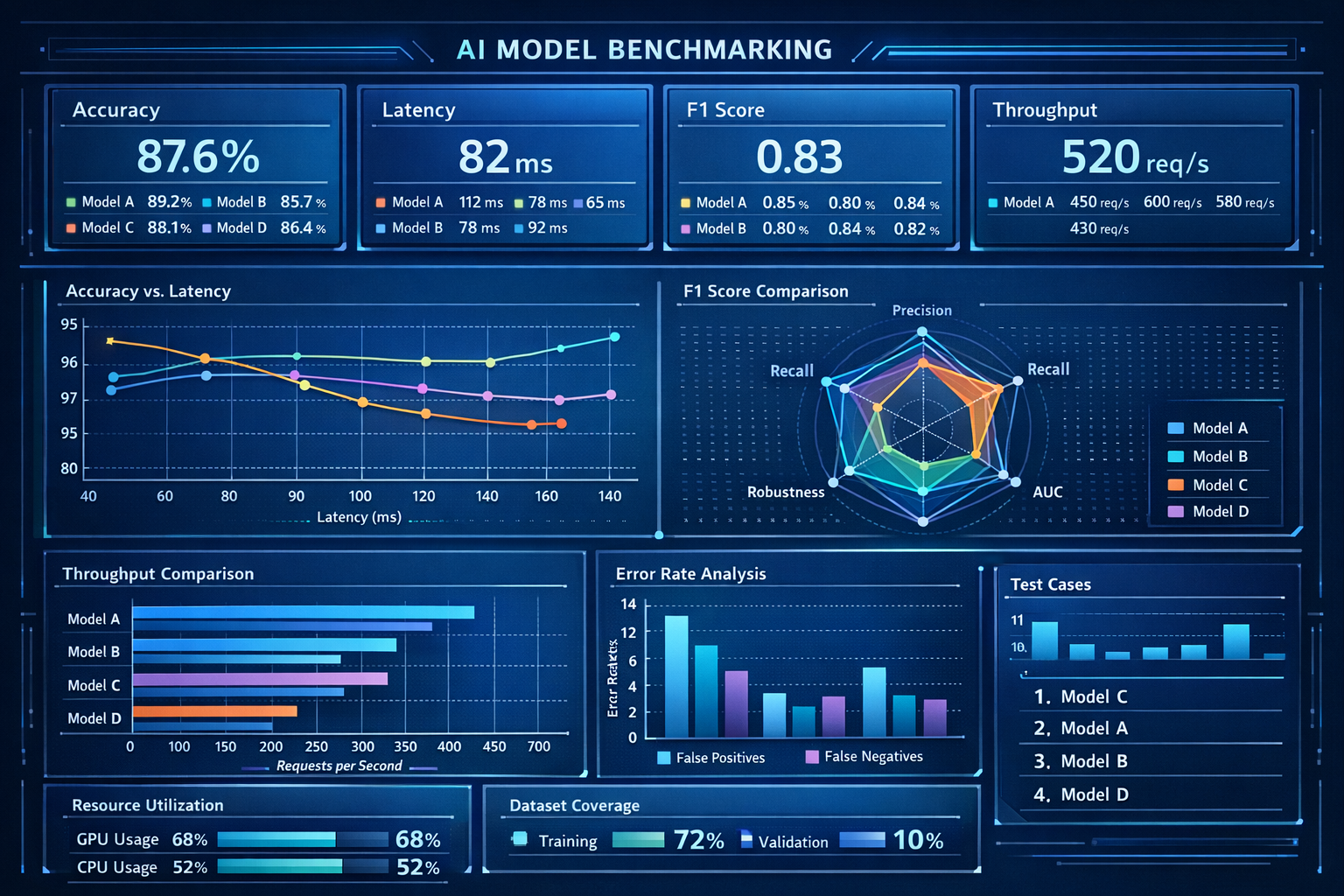
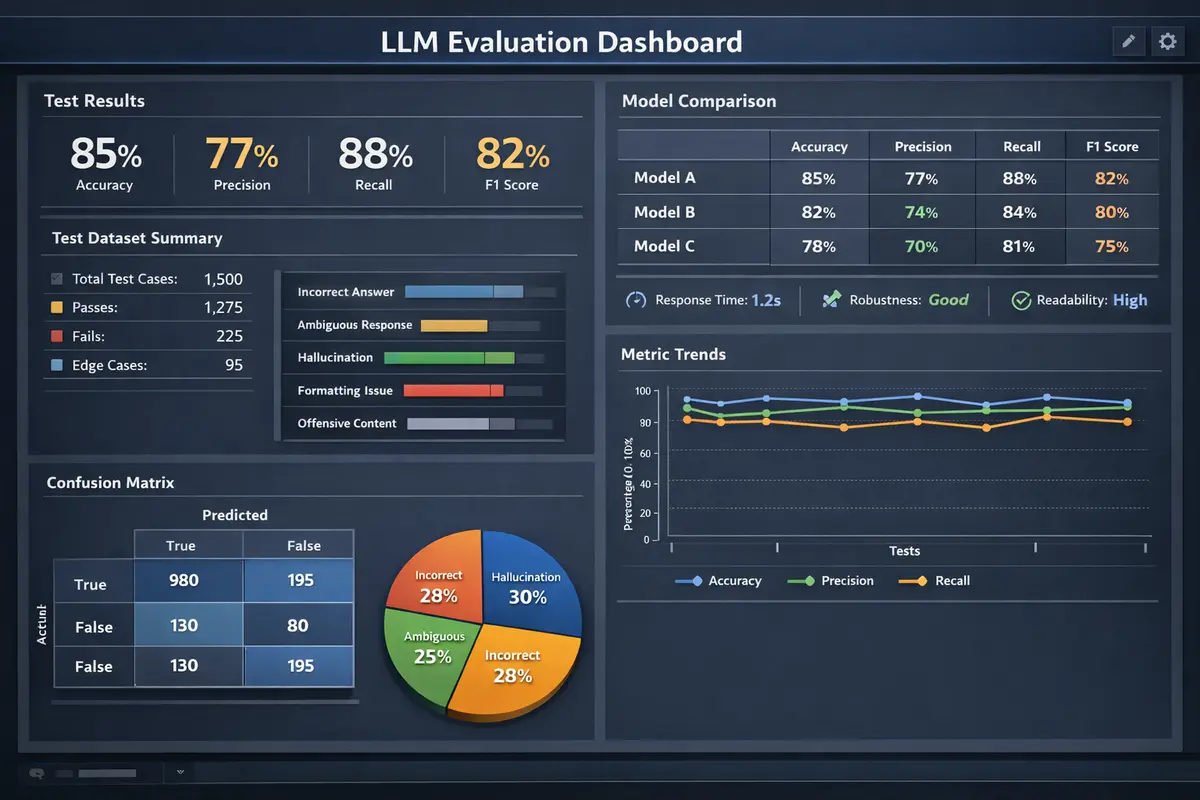
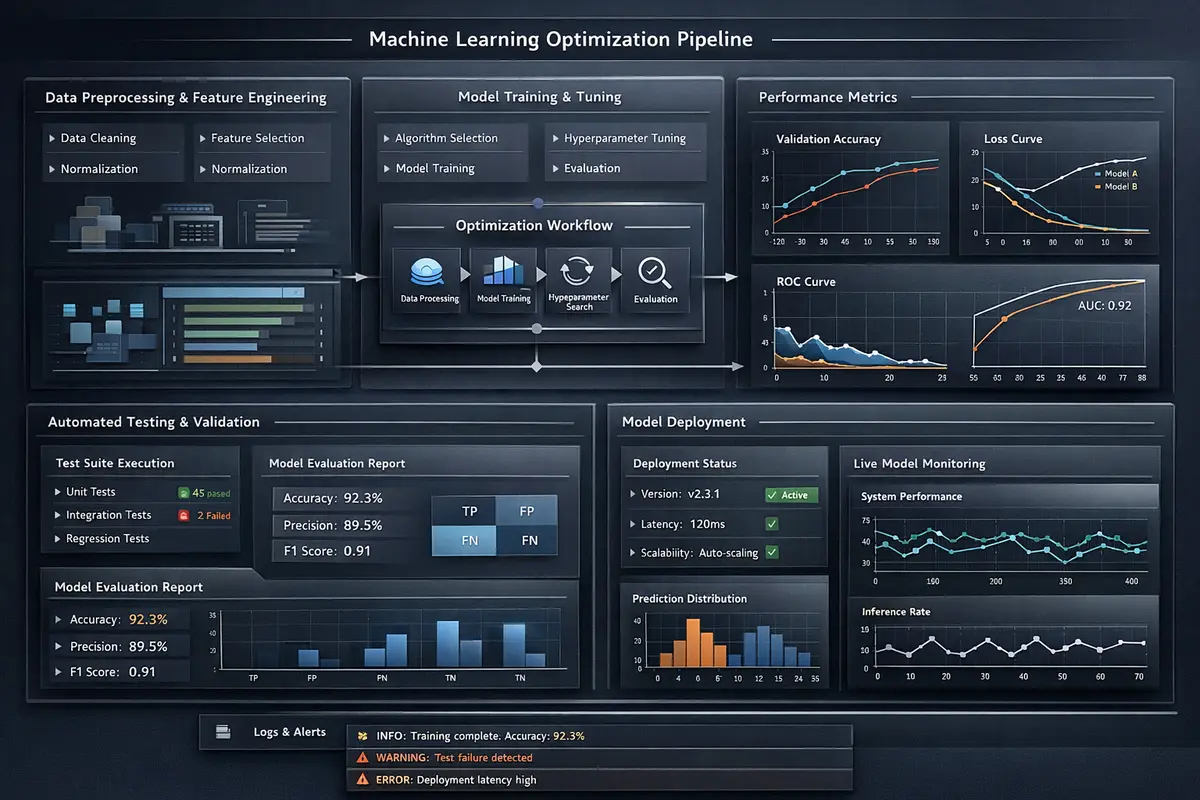
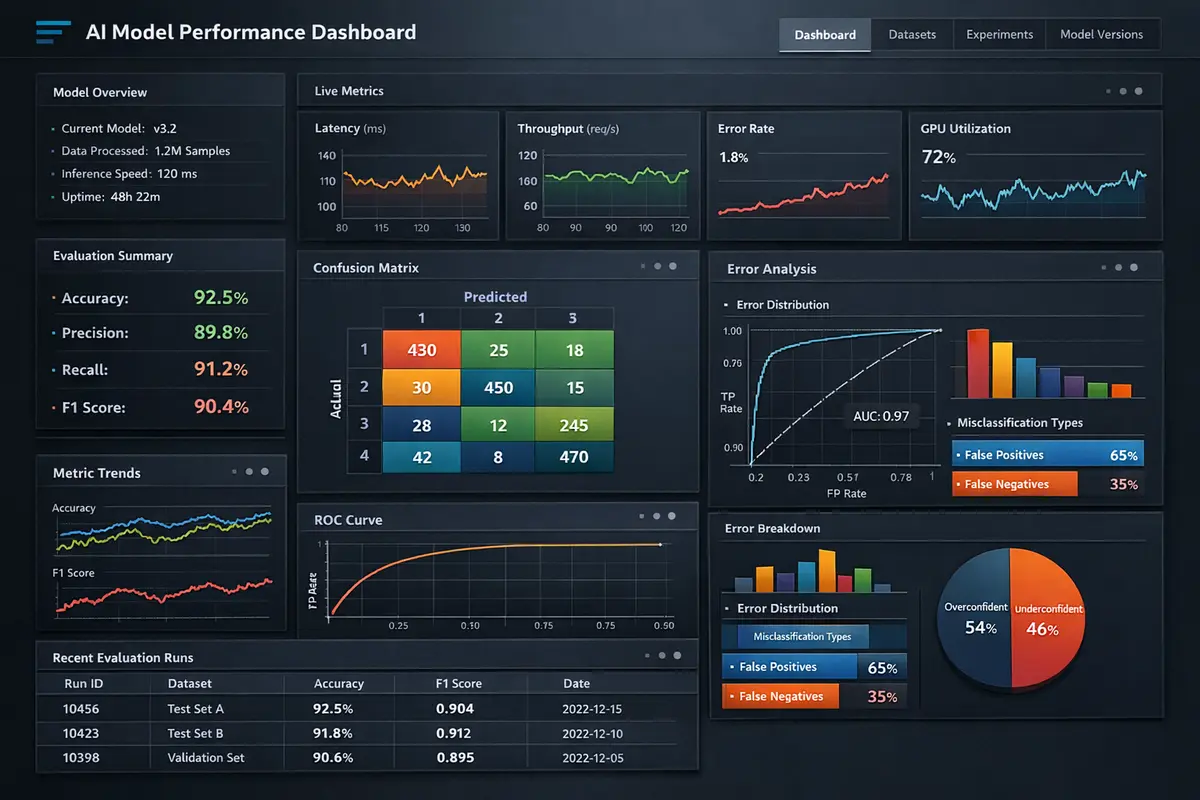
Every evaluation follows a reproducible protocol designed to eliminate the confounding variables that plague ad hoc model testing. Test suites are defined as JSON manifests that specify the exact prompts, system instructions, sampling parameters (temperature, top-p, top-k), expected behavior criteria, and scoring rubrics. The framework executes each test against the target model configuration, captures raw outputs with full token-level probability distributions where available, applies automated scoring functions, and generates summary statistics with confidence intervals.
Results are persisted in SQLite with comprehensive provenance metadata including the model identifier, quantization format and parameters, hardware configuration (GPU model, driver version, CUDA version), inference framework and version, system load at test time, and a SHA-256 hash of the test suite definition. This level of provenance enables longitudinal analysis across model updates, allowing teams to detect behavioral regressions that emerge when a provider releases a new model version or when quantization parameters are adjusted.
Security and Adversarial Testing
Enterprise AI deployments require rigorous security testing before production release. The framework includes structured assessment modules that probe model behavior across adversarial inputs, boundary conditions, and compliance-sensitive scenarios. Test categories cover prompt injection resistance, system prompt extraction attempts, output consistency under paraphrased inputs, and behavior with multilingual inputs designed to bypass English-language safety filters. Results are categorized by severity level and mapped to organizational risk frameworks, enabling security teams to produce deployment readiness certificates. All assessment results export in JSON and PDF formats for integration with existing governance workflows, audit documentation, and regulatory compliance filings.