Investor Summary
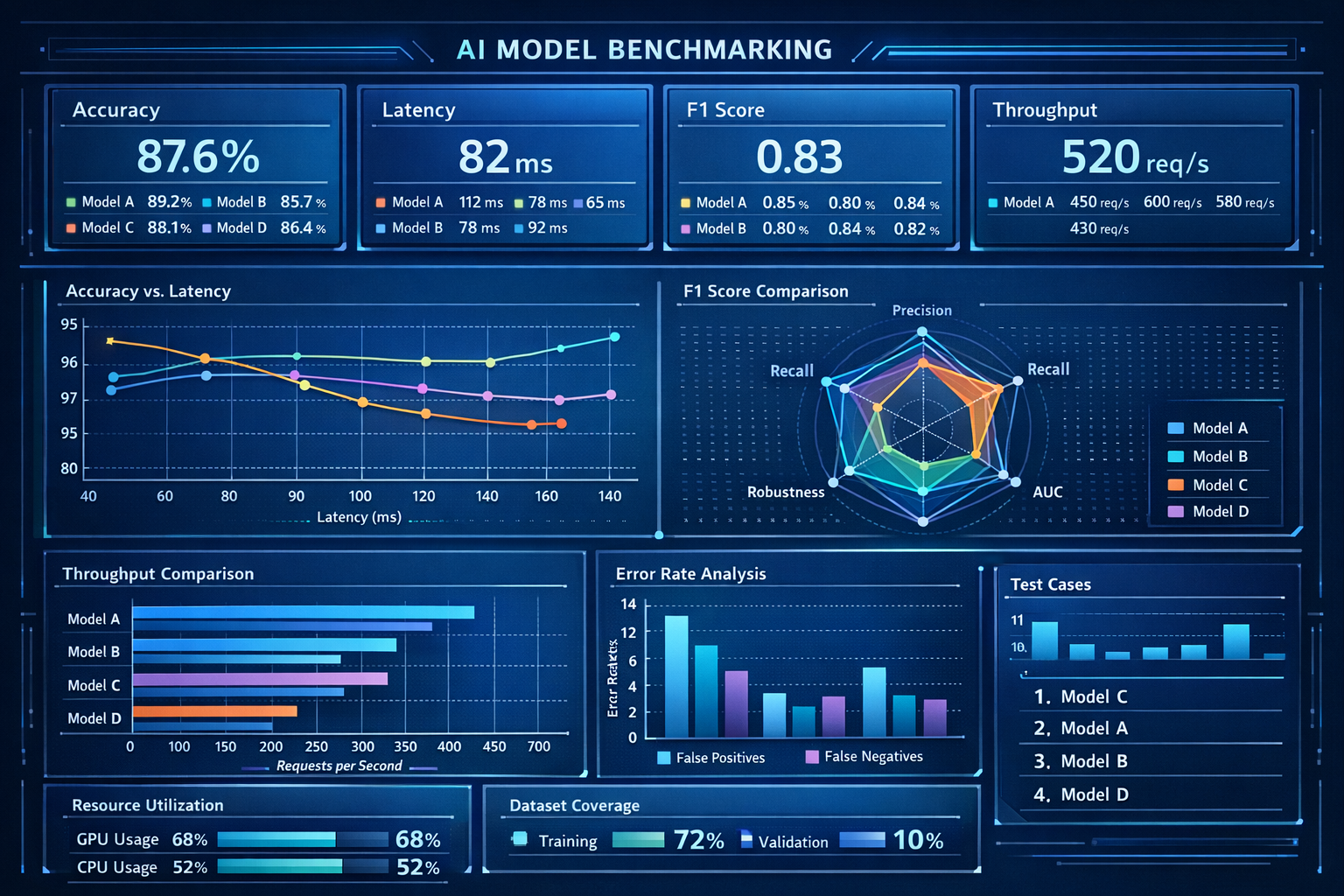
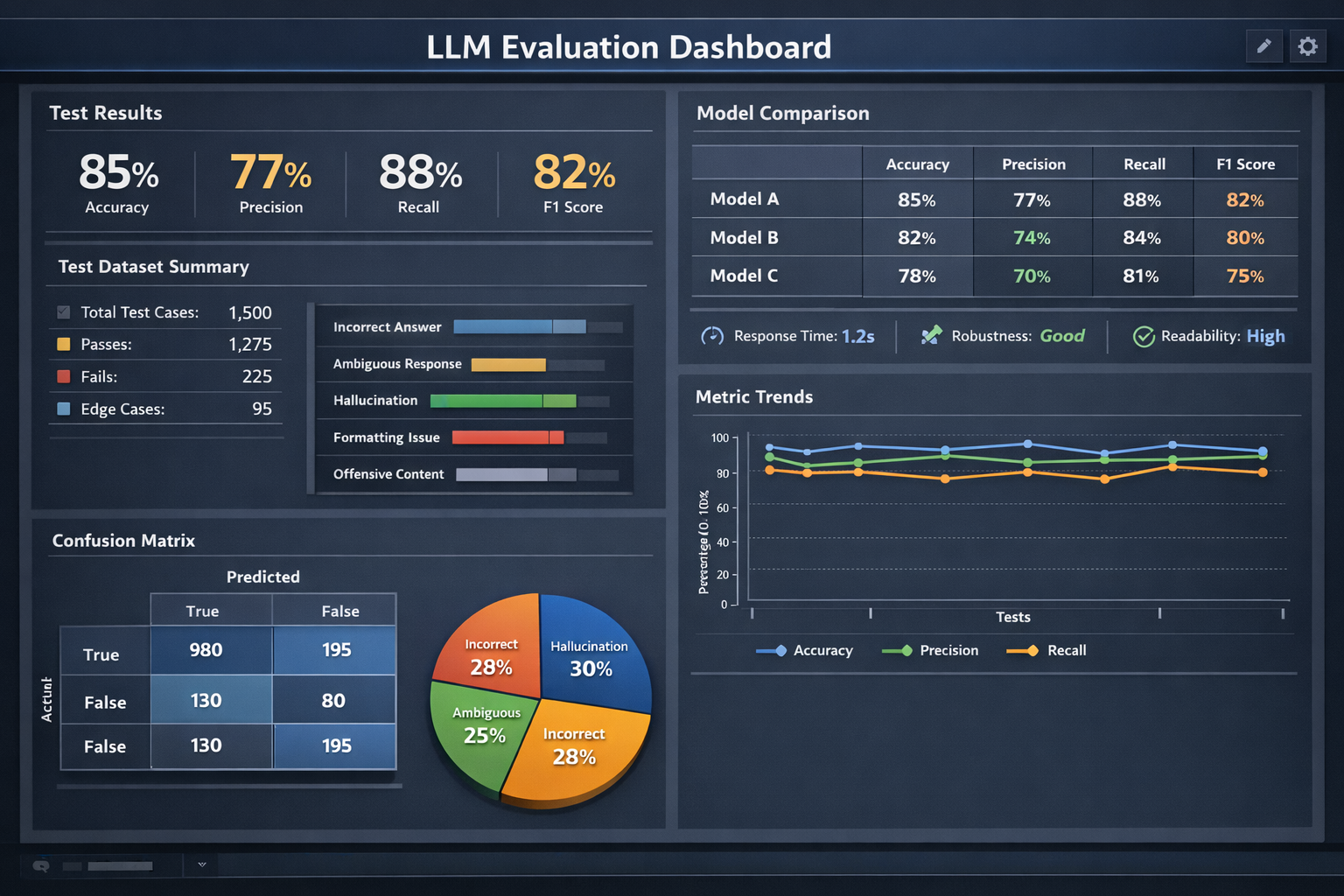
As AI adoption accelerates, companies need repeatable evaluation and security testing for model behavior. This framework provides a structured approach to catalog techniques, record evaluations, and present results in a dashboard-friendly format suitable for research and decision making.
The $300B+ enterprise AI market demands rigorous evaluation tooling. By combining structured technique taxonomy with interactive visualization, we enable organizations to understand, test, and improve their AI systems with confidence. As regulatory frameworks like the EU AI Act introduce mandatory model evaluation requirements, organizations that lack systematic testing infrastructure face both compliance risk and competitive disadvantage.
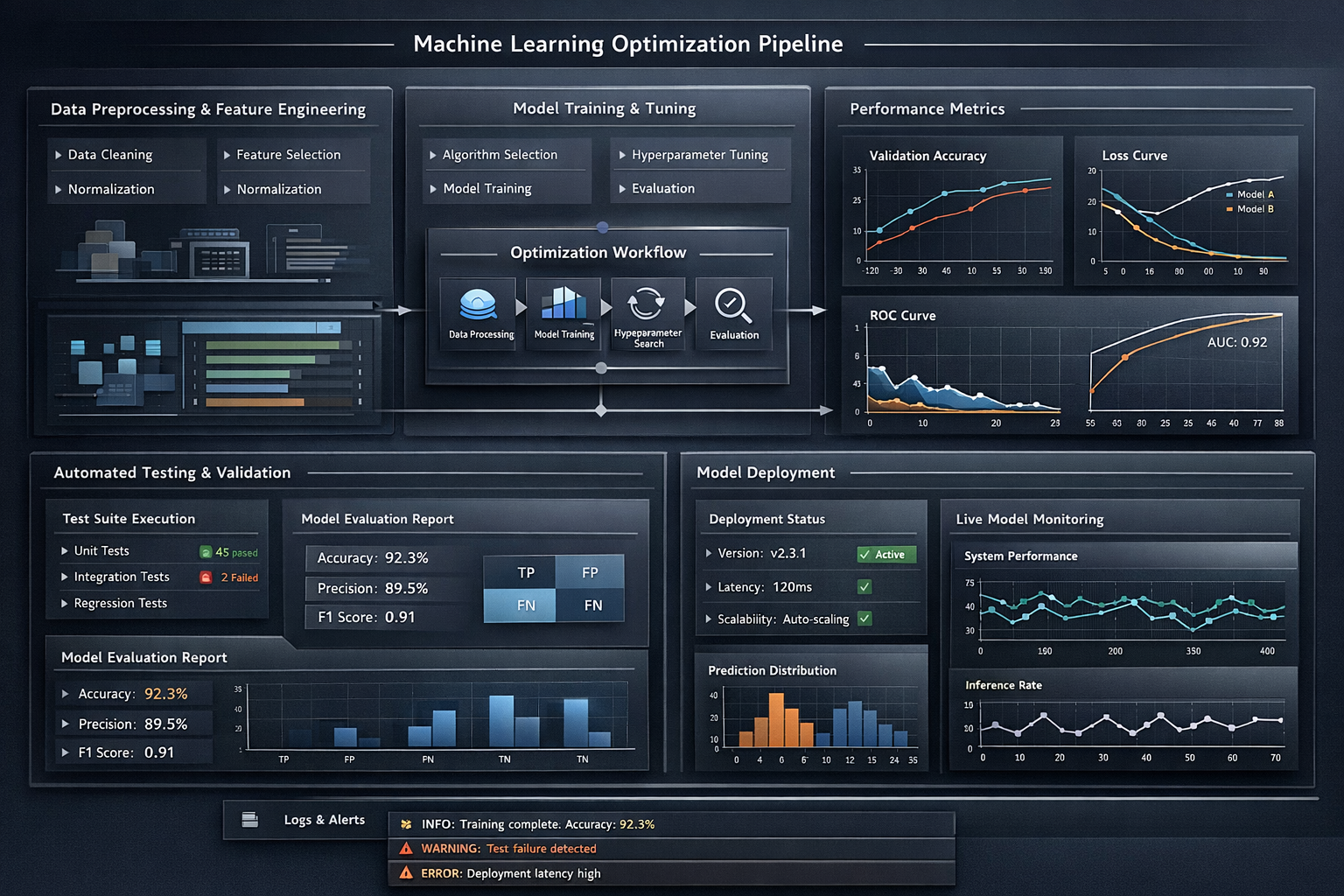
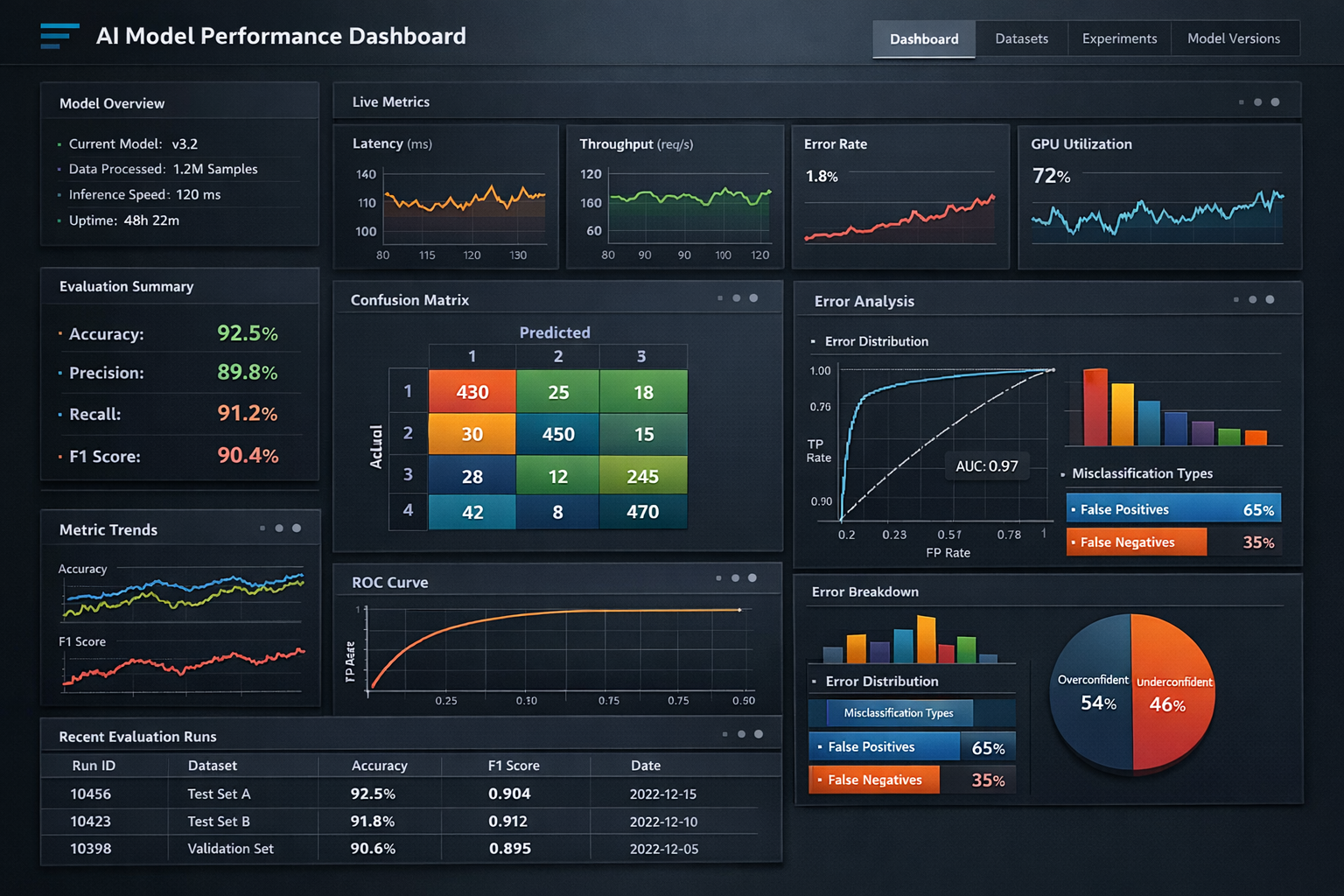
Our framework addresses the full lifecycle of LLM evaluation, from initial model selection through production monitoring. Rather than treating model assessment as a one-time event, the platform establishes continuous evaluation pipelines that track behavioral drift, measure inference performance across hardware configurations, and produce auditable reports for stakeholders ranging from engineering teams to board-level governance committees.