Investor Summary
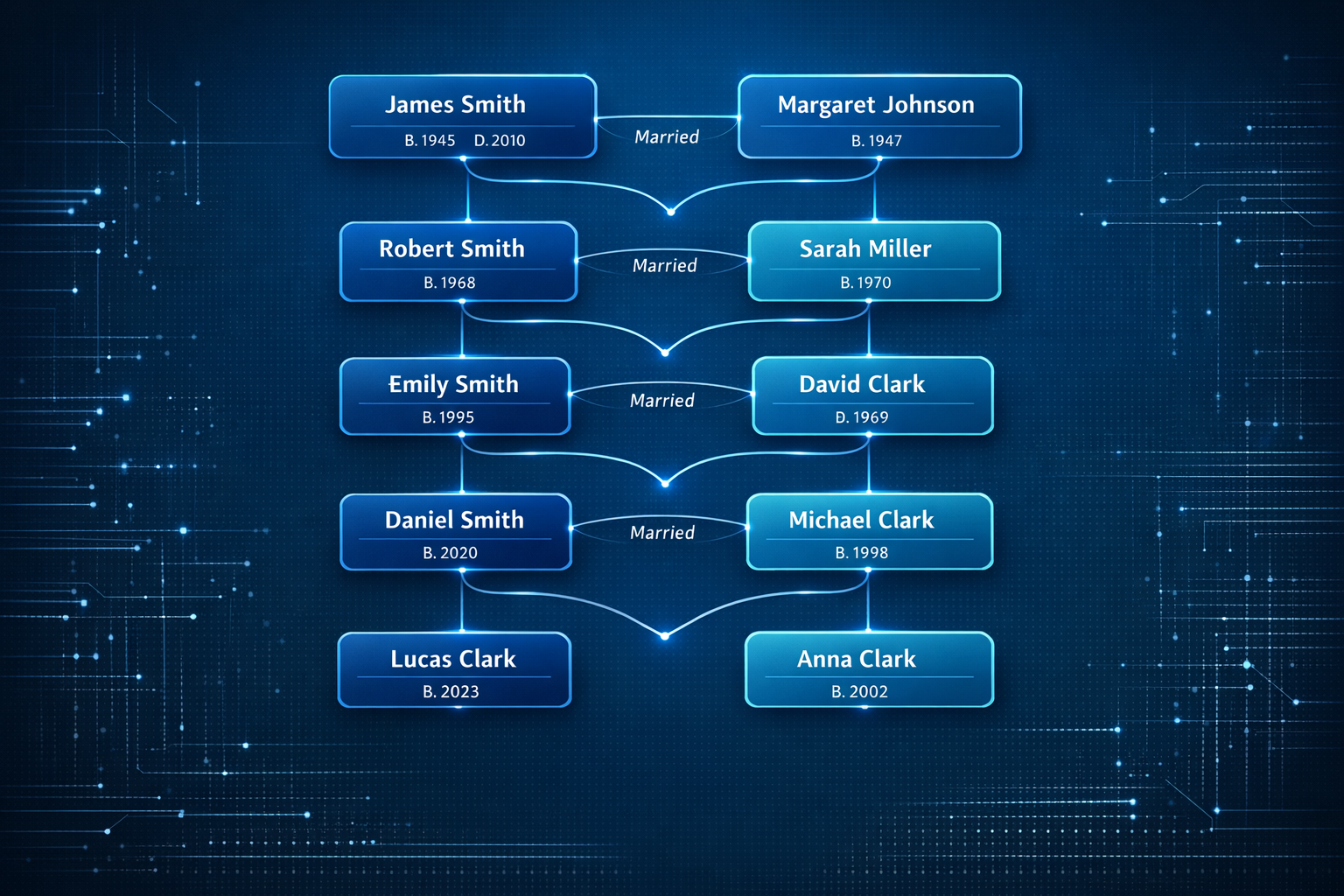
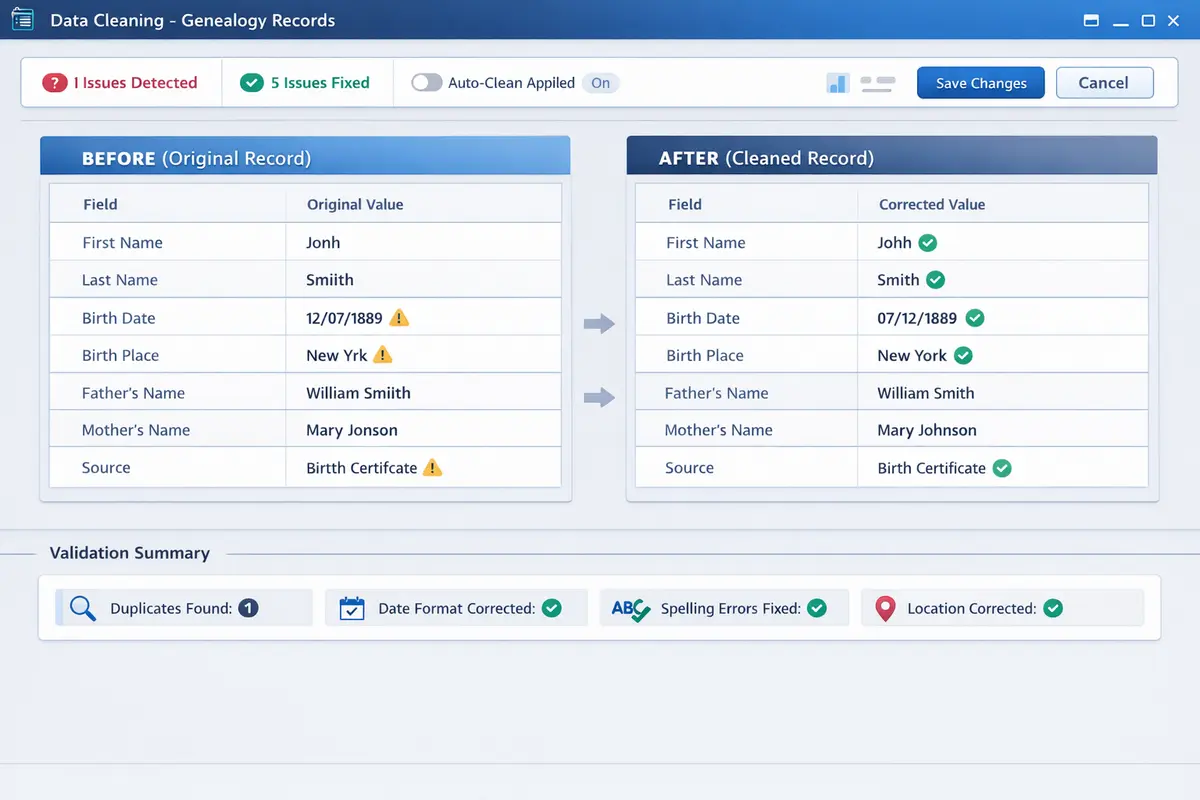
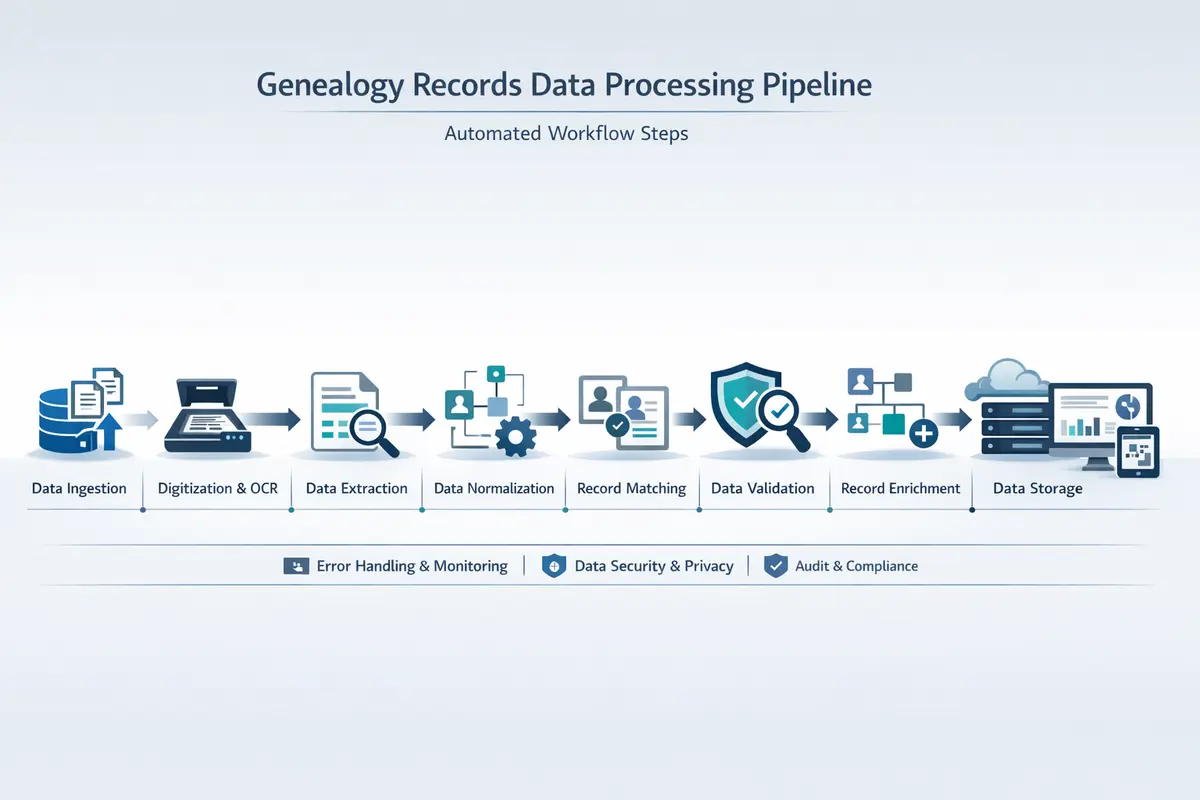
Genealogy data is high-value but messy, fragmented, and expensive to clean. This project delivers an automated, integrity-first pipeline that transforms raw GEDCOM files into standardized, import-ready assets while preserving every relationship. It combines a reusable Python library, a CLI, and a full processing workflow designed for repeatable, professional-grade outcomes.
The genealogy market continues to grow as genetic testing services expand and millions of consumers build digital family trees across platforms like Ancestry, FamilySearch, and MyHeritage. GEDCOM, the universal standard for genealogical data exchange, has been in use since 1984, and decades of files created by different software, in different languages, with different naming and date conventions have produced a massive corpus of data that is technically interoperable but practically inconsistent. Professional genealogists and archival organizations spend thousands of hours manually reviewing records, resolving duplicates, and standardizing formats before data can be migrated between platforms or published in authoritative databases. Our platform automates this work with surgical precision while maintaining the zero-data-loss guarantee that genealogy professionals require.
The platform architecture is deliberately dual-mode: the gedfix Python library can be imported as a dependency into larger systems including web applications, SaaS platforms, and batch processing pipelines, while the CLI provides a standalone tool for professional genealogists who need immediate access to the full processing capability without writing code. This dual distribution strategy maximizes addressable market by serving both enterprise integration buyers and individual professional users from a single codebase with shared validation logic and processing algorithms.