Investor Summary
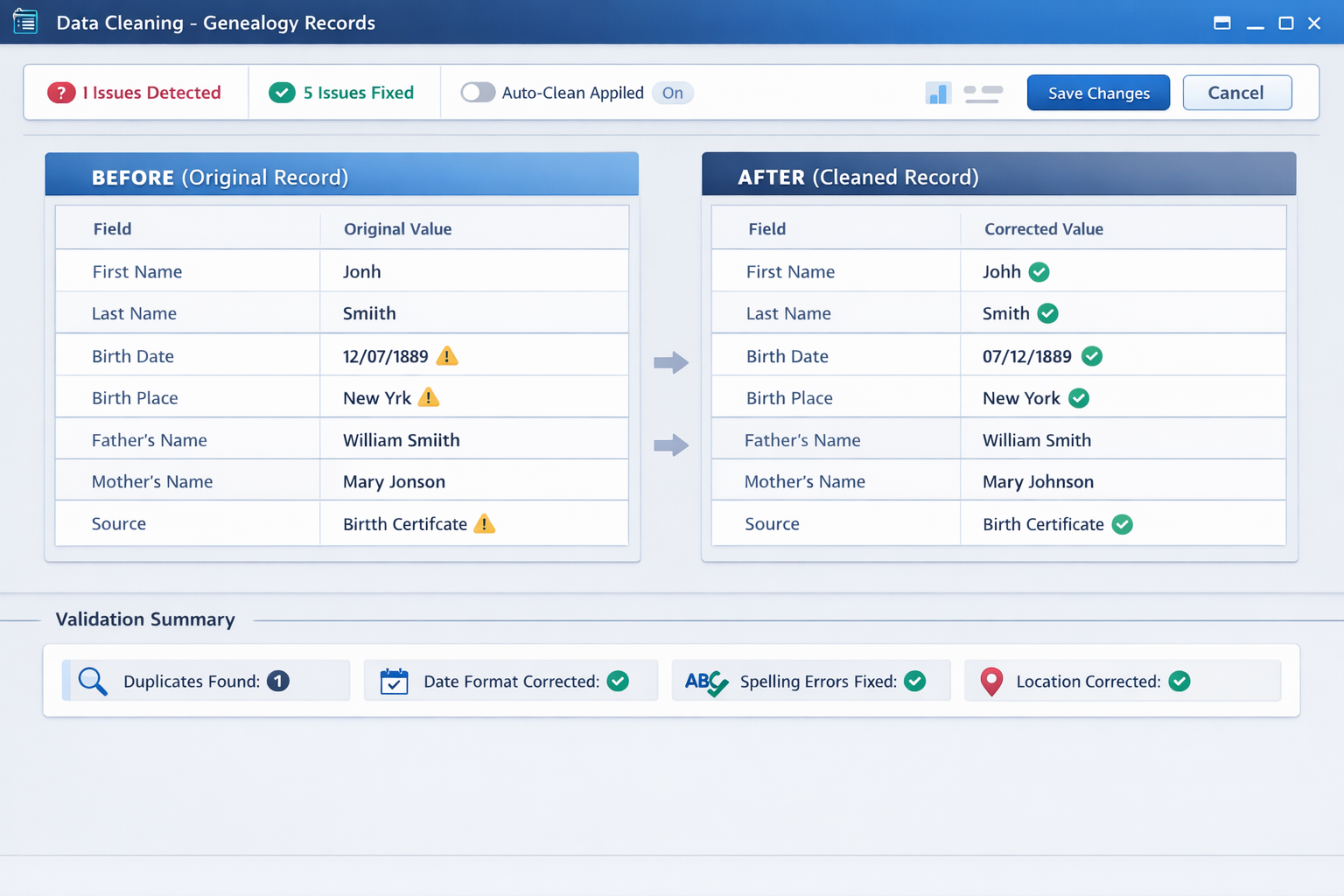
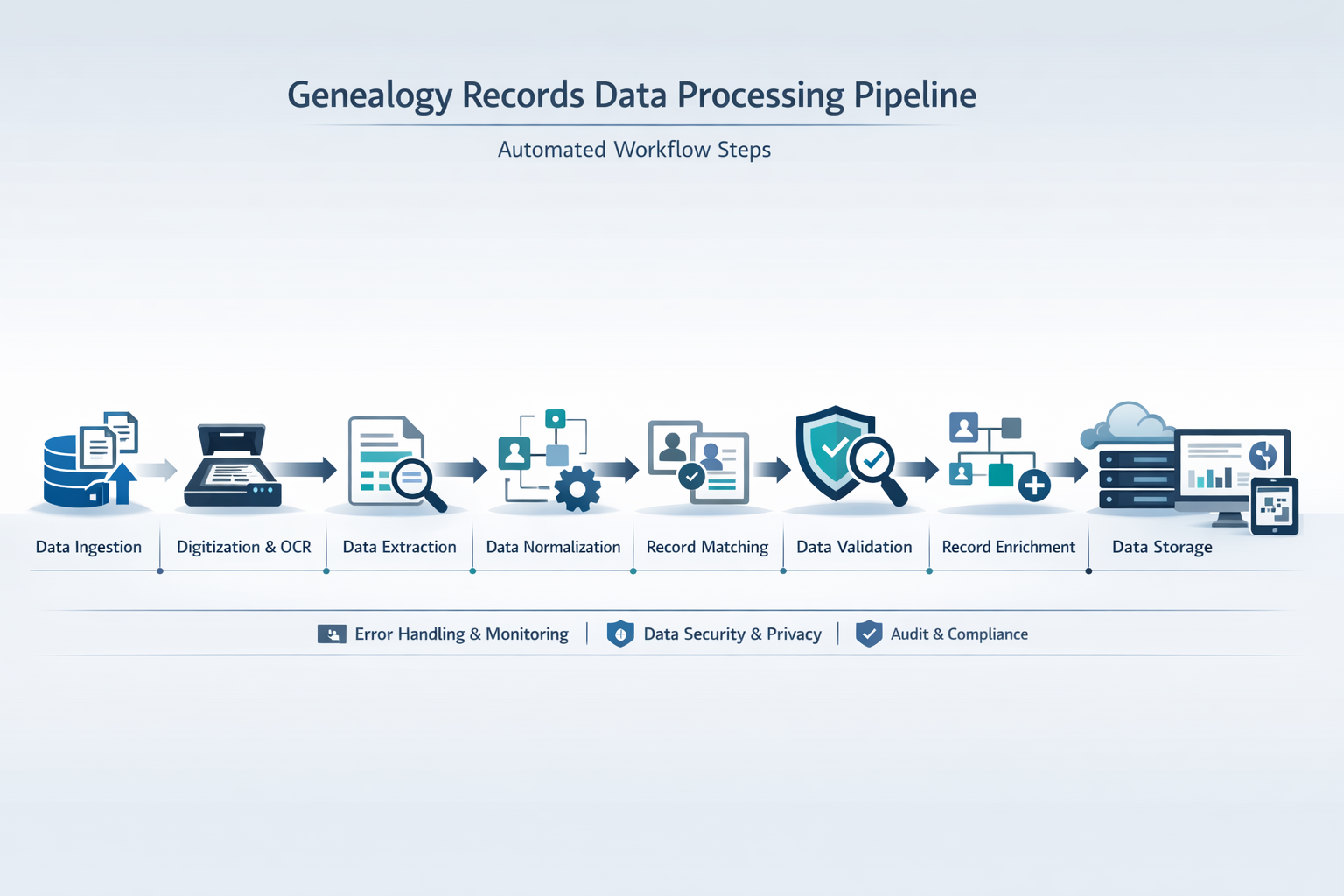
Genealogy data is high-value but messy, fragmented, and expensive to clean. This project delivers an automated, integrity-first pipeline that transforms raw GEDCOM files into standardized, import-ready assets while preserving every relationship.
The $4B+ genealogy market demands professional-grade data processing. By combining a reusable Python library with a CLI and full processing workflow, we enable organizations to perform repeatable, auditable data migrations at scale. As genetic testing services expand and millions of consumers build digital family trees, the demand for reliable data normalization infrastructure is growing faster than existing solutions can serve.
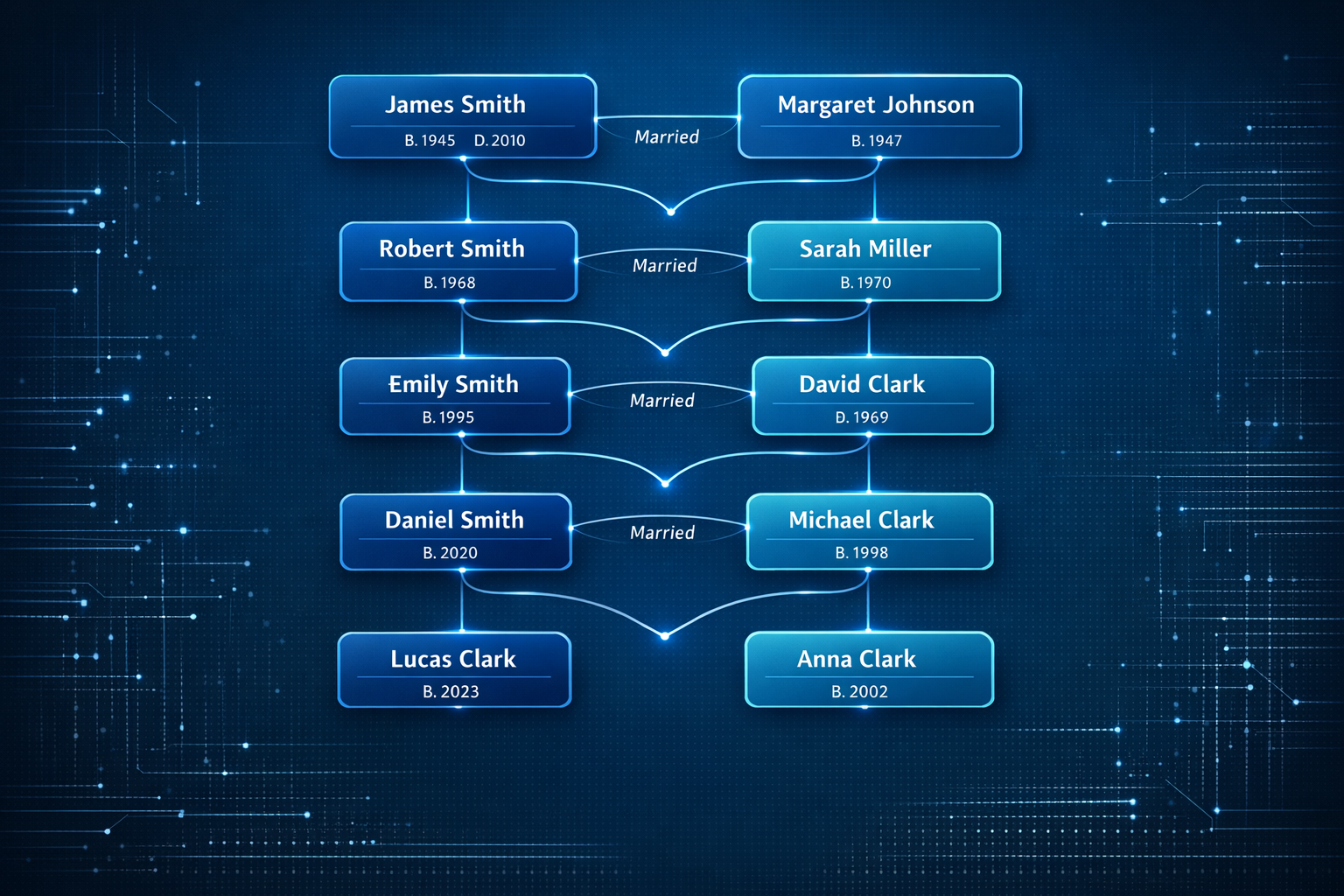
GEDCOM, the universal standard for genealogical data exchange, has been in use since 1984. Decades of files created by different software, in different languages, with different conventions have produced a massive corpus of data that is technically interoperable but practically inconsistent. Our platform addresses this gap with surgical precision, turning fragmented records into research-grade datasets that genealogists and archivists can trust.