Investor Summary
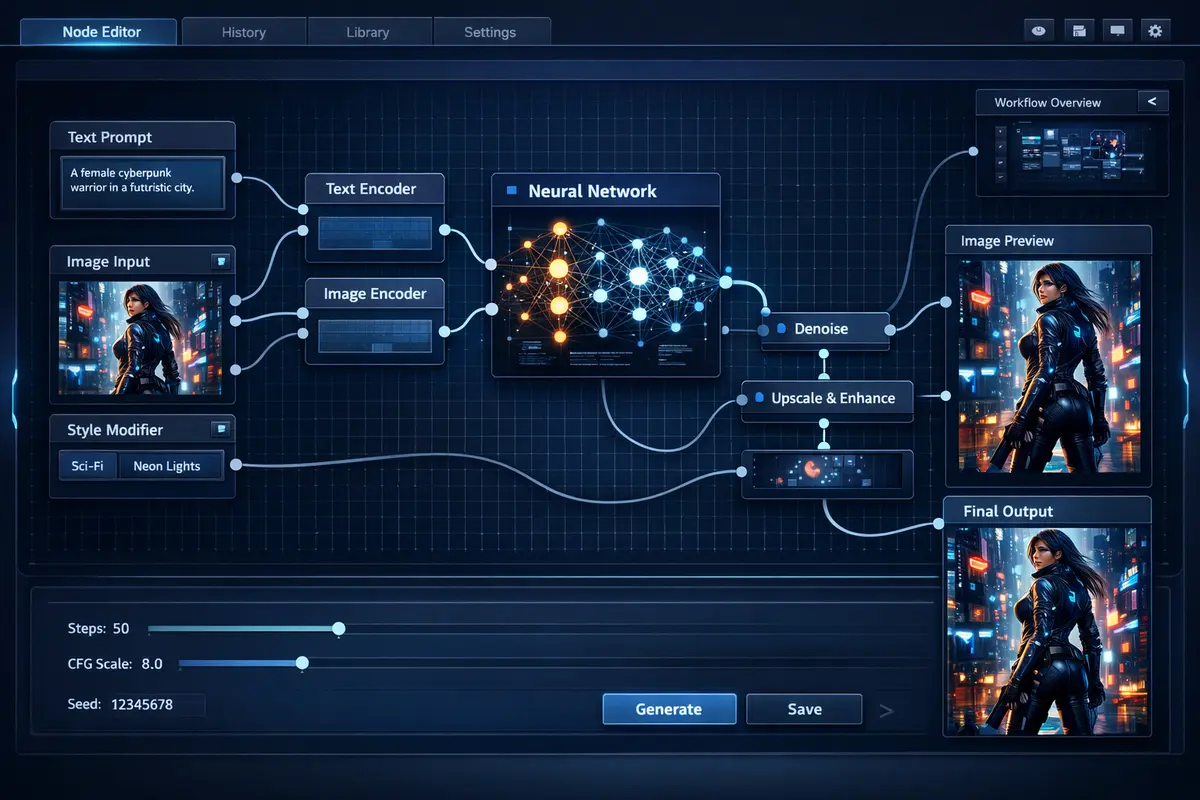
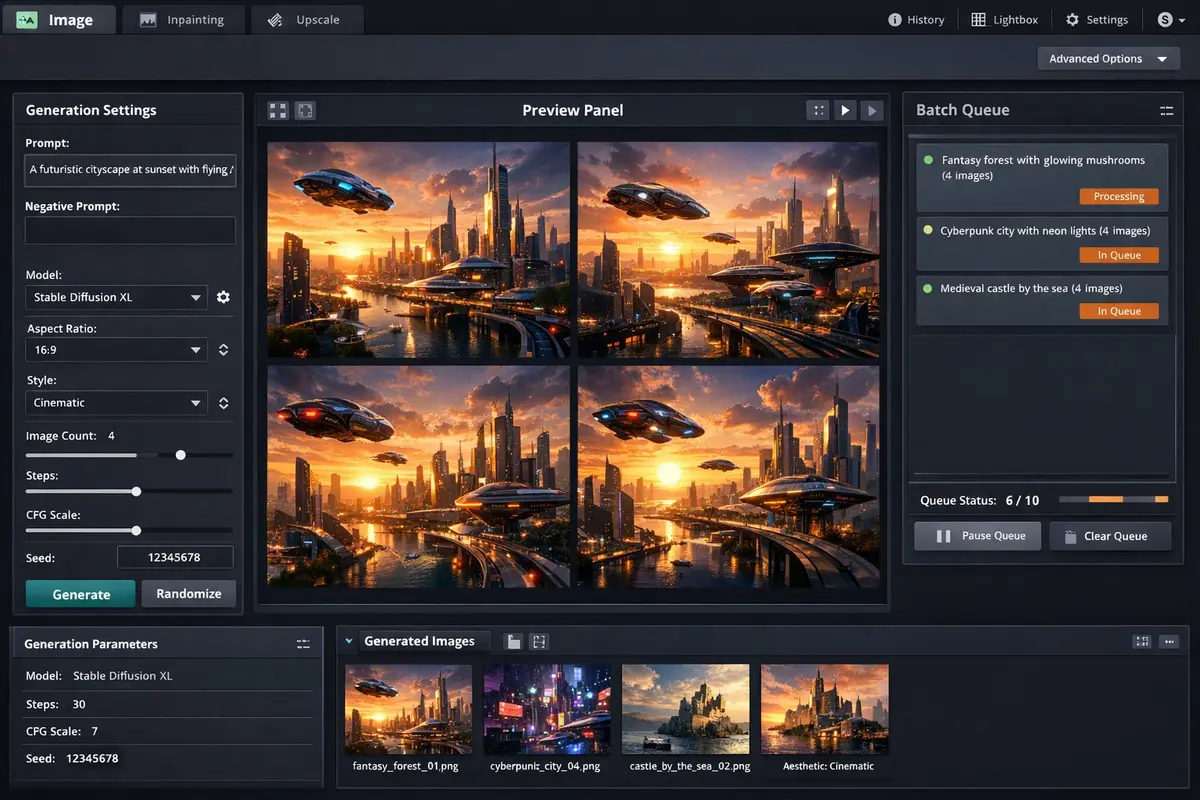
Generative image workflows are often fragile, manual, and difficult to scale. This project provides a programmatic automation layer over ComfyUI, delivering reproducible workflows, batch generation, and LoRA management that turns a UI-driven system into a scalable production pipeline suitable for enterprise creative operations.
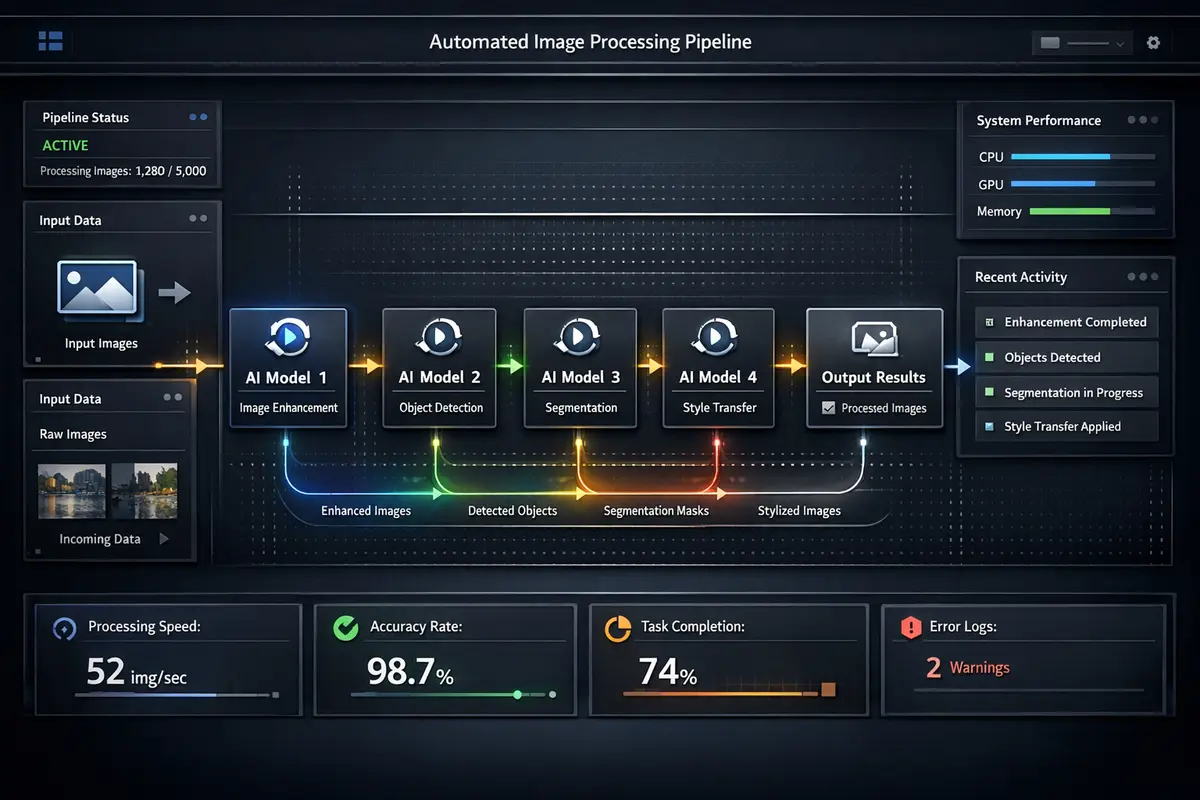
The generative AI market demands enterprise-grade tooling that bridges the gap between creative experimentation and production deployment. Most generative AI tools require manual interaction for each output, making them unsuitable for campaigns requiring hundreds or thousands of consistent assets. By abstracting ComfyUI's node-graph complexity behind a configuration-driven API, we enable creative teams to scale from single images to massive batch runs while maintaining brand consistency, quality standards, and full reproducibility across every generated asset. The platform supports the complete spectrum of modern generative models including Stable Diffusion XL, Flux Dev, Flux Schnell, and WAN video generation models, each accessible through the same unified programmatic interface.
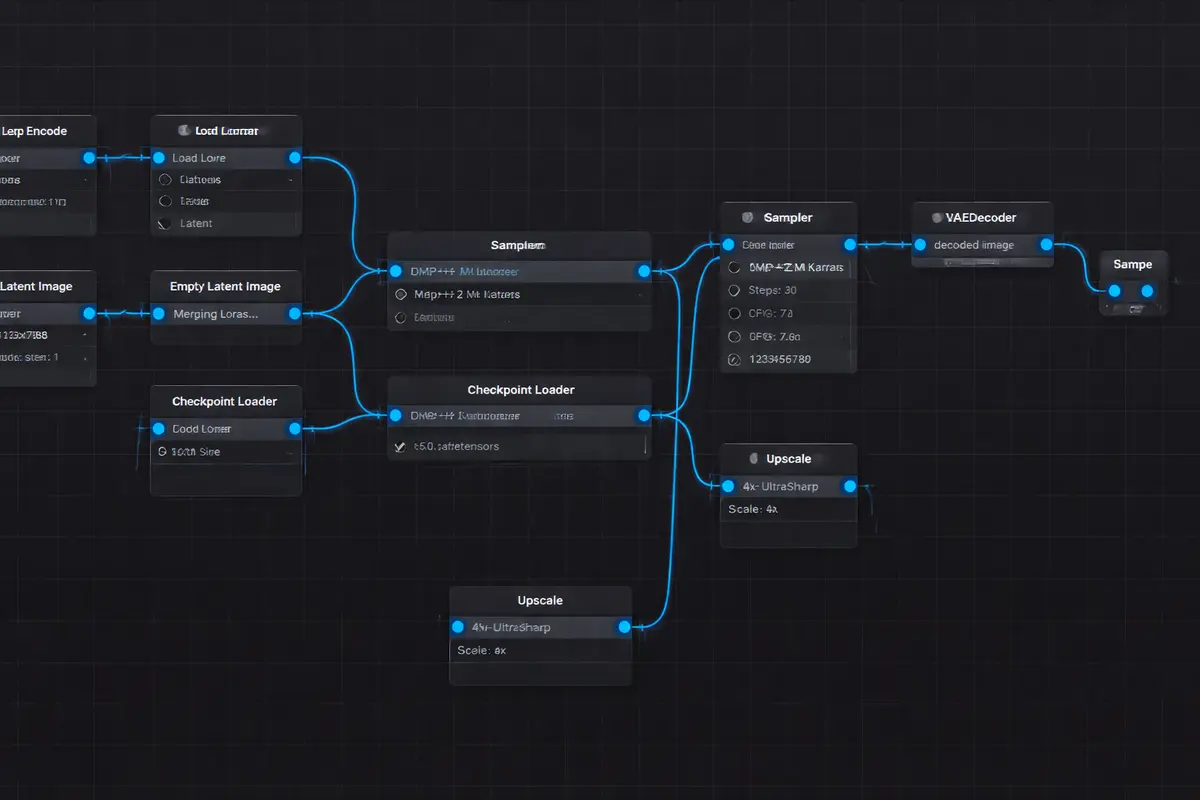
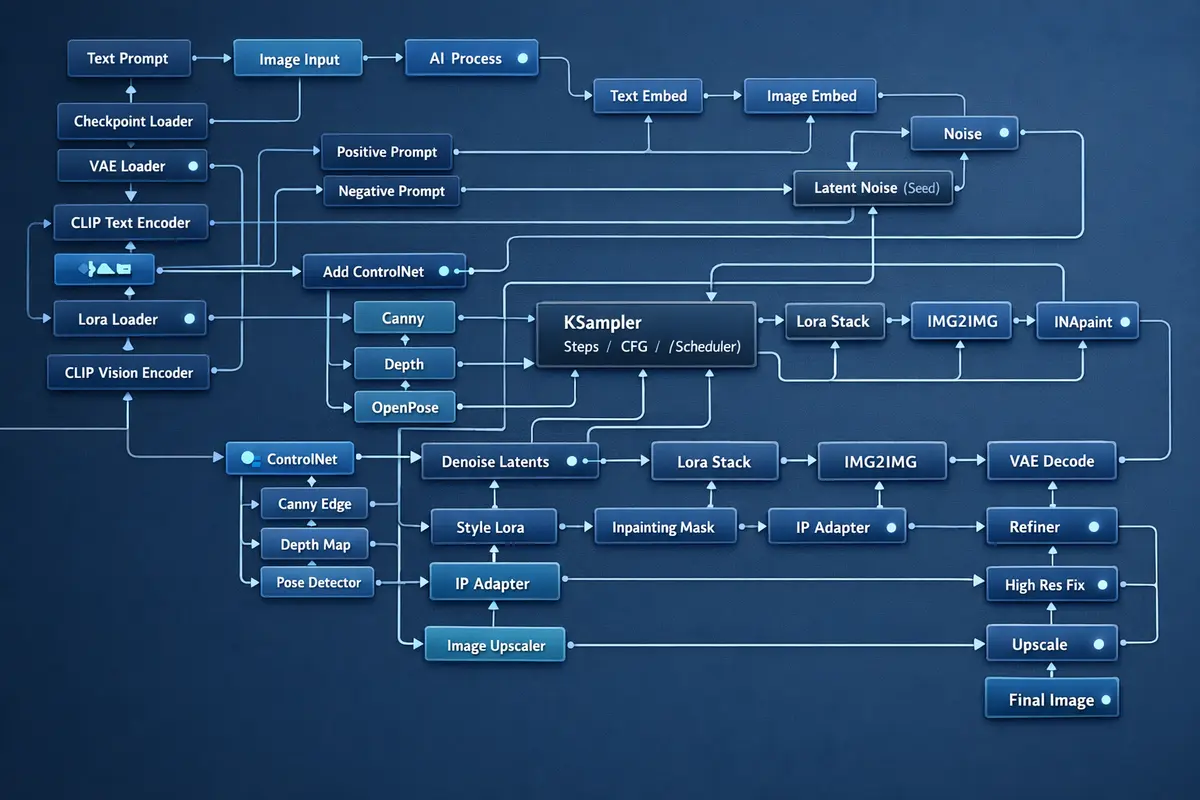
Every workflow is serialized as a JSON artifact containing the complete node graph, model references, sampler configuration, seed values, and LoRA weight assignments. This serialization enables version control of generation configurations, deterministic reproduction of any previously generated output, and A/B testing of prompt strategies with measurable quality comparisons. For organizations operating in regulated industries where provenance documentation is mandatory, the metadata chain provides an auditable record connecting every generated asset to its exact generation parameters.